2023-08-03 18:38:21 +08:00
|
|
|
|
title: 使用油猴脚本保存极客时间文章
|
|
|
|
|
|
tags: []
|
|
|
|
|
|
categories: []
|
|
|
|
|
|
date: 2023-08-03 16:58:17
|
|
|
|
|
|
---
|
|
|
|
|
|
# 背景
|
|
|
|
|
|
|
|
|
|
|
|
去年购买了极客时间的年度会员,只有一年有效期。所以想用一些方式保存一下来购买的内容。市面上没有成熟的方案,所以决定自己编写
|
|
|
|
|
|
|
|
|
|
|
|
# 使用前提
|
|
|
|
|
|
开始前需要读者具备一定的开发基础。最好会点简单的JS。能使用浏览器开发者工具
|
|
|
|
|
|
需要准备以下内容:
|
|
|
|
|
|
1. edge 或chrome 并安装油猴插件
|
|
|
|
|
|
2. 文本编辑器
|
|
|
|
|
|
3. 一双手(逃)
|
|
|
|
|
|
|
|
|
|
|
|
# 分析网站
|
|
|
|
|
|
|
|
|
|
|
|
分析网站分析什么?
|
|
|
|
|
|
主要分析页面及各种HTTP请求,哪种对我们更便捷。
|
|
|
|
|
|
## 页面抓取可行性
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
问题:
|
|
|
|
|
|
1. 超链接无法抓取到
|
|
|
|
|
|
|
|
|
|
|
|
## 请求抓取可行性
|
|
|
|
|
|
现代的互联网公司的网站,基本都是前后端分离的,也就是请求的数据基本都是JSON,这为抓取数据带来了便利。
|
|
|
|
|
|
|
|
|
|
|
|
**找到请求正文的请求**
|
|
|
|
|
|
页面刷新一下,在所有网络请求一个一个看返回内容
|
|
|
|
|
|
|
|
|
|
|
|
找到真正的获取正文请求是`https://time.geekbang.org/serv/v1/article`,该请求是一个POST请求。看一下POST的数据
|
|
|
|
|
|
```json
|
|
|
|
|
|
{
|
|
|
|
|
|
"id":***,
|
|
|
|
|
|
"include_neighbors":true,
|
|
|
|
|
|
"is_freelyread":true
|
|
|
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
其他的不要在意,看一下这个ID,是不是和页面路径的`https://time.geekbang.org/column/article/***`后的ID一样?
|
|
|
|
|
|
那就简单了,拿到页面的URL把ID取出来
|
|
|
|
|
|
|
|
|
|
|
|
然后分析返回内容
|
|
|
|
|
|
|
|
|
|
|
|
这里展示核心内容
|
|
|
|
|
|
```json
|
|
|
|
|
|
{
|
|
|
|
|
|
"data":{
|
|
|
|
|
|
"text_read_version":0,
|
|
|
|
|
|
"audio_size":10270592,
|
|
|
|
|
|
"product_type":"p29",
|
|
|
|
|
|
"audio_dubber":"霍泰稳",
|
|
|
|
|
|
"is_finished":false,
|
|
|
|
|
|
"like":{
|
|
|
|
|
|
"had_done":false,
|
|
|
|
|
|
"count":0
|
|
|
|
|
|
},
|
|
|
|
|
|
"article_content":"****",
|
|
|
|
|
|
"article_title":"第306期 | 放下纠结,你就远离了拖延症",
|
|
|
|
|
|
"article_cshort":"今天和大家分享一个关于拖延症的话题,我猜这个话题会有很多人感兴趣。",
|
|
|
|
|
|
"author_name":"霍太稳",
|
|
|
|
|
|
"neighbors":{
|
|
|
|
|
|
"left":{
|
|
|
|
|
|
"article_title":"第305期 | 开心的时候,去跑步,心烦的时候,去跑步",
|
|
|
|
|
|
"id":256918
|
|
|
|
|
|
},
|
|
|
|
|
|
"right":{
|
|
|
|
|
|
"article_title":"第307期 | 幸福其实很简单,忘掉自己就好",
|
|
|
|
|
|
"id":257894
|
|
|
|
|
|
}
|
|
|
|
|
|
},
|
|
|
|
|
|
"product_id":100024801,
|
|
|
|
|
|
"had_liked":false,
|
|
|
|
|
|
"id":257009,
|
|
|
|
|
|
"article_summary":"今天和大家分享一个关于拖延症的话题,我猜这个话题会有很多人感兴趣。",
|
|
|
|
|
|
"column_id":172,
|
|
|
|
|
|
"audio_md5":"de4f0391304d351d9c5dd6e93f038356"
|
|
|
|
|
|
},
|
|
|
|
|
|
"code":0
|
|
|
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
注意看`article_content` 这里就是文章正文。我们只需要抓这部分就好了。
|
|
|
|
|
|
因为抓取请求相对比较麻烦,所以我们再发起一次请求,拿到返回内容更简单。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
# 开始编写
|
|
|
|
|
|
1. 引入JQuery
|
|
|
|
|
|
2. 设定可行的页面
|
|
|
|
|
|
|
|
|
|
|
|
```js
|
|
|
|
|
|
// ==UserScript==
|
|
|
|
|
|
// @name 保存极客时间正文
|
|
|
|
|
|
// @namespace http://tampermonkey.net/
|
|
|
|
|
|
// @version 0.1
|
|
|
|
|
|
// @match https://time.geekbang.org/column/article/*
|
|
|
|
|
|
// @description try to take over the world!
|
|
|
|
|
|
// @author You
|
|
|
|
|
|
// @require https://cdn.bootcss.com/jquery/1.12.4/jquery.min.js
|
|
|
|
|
|
// @grant none
|
|
|
|
|
|
// ==/UserScript==
|
|
|
|
|
|
|
|
|
|
|
|
(function () {
|
|
|
|
|
|
'use strict';
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
let btn = document.createElement("button");
|
|
|
|
|
|
btn.innerHTML = "下载";
|
|
|
|
|
|
btn.style = "position: fixed;z-index: 999; left: 90%; top: 20px;";
|
|
|
|
|
|
|
|
|
|
|
|
btn.onclick = function () {
|
|
|
|
|
|
//code
|
|
|
|
|
|
saveContext()
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
document.body.append(btn);
|
|
|
|
|
|
function saveContext() {
|
|
|
|
|
|
var url = window.location.href
|
|
|
|
|
|
var id = url.replace("https://time.geekbang.org/column/article/", "")
|
|
|
|
|
|
var json = { "id": id, "include_neighbors": true, "is_freelyread": true }
|
|
|
|
|
|
|
|
|
|
|
|
$.ajax({
|
|
|
|
|
|
url: "https://time.geekbang.org/serv/v1/article",
|
|
|
|
|
|
data: JSON.stringify(json),
|
|
|
|
|
|
type: "POST",
|
|
|
|
|
|
dataType: "json",
|
|
|
|
|
|
contentType: "application/json",
|
|
|
|
|
|
success: function (data) {
|
|
|
|
|
|
console.log(data);
|
|
|
|
|
|
var context = data.data.article_content;
|
|
|
|
|
|
var title = data.data.article_title;
|
|
|
|
|
|
|
|
|
|
|
|
const link = document.createElement('a');
|
|
|
|
|
|
|
|
|
|
|
|
var textBlob = new Blob([context], { type: 'text/plain' });
|
|
|
|
|
|
|
|
|
|
|
|
link.setAttribute('href', URL.createObjectURL(textBlob));
|
|
|
|
|
|
link.setAttribute('download', title + ".html");
|
|
|
|
|
|
link.click();
|
|
|
|
|
|
}
|
|
|
|
|
|
});
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
})();
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
以上内容直接贴到新脚本即可使用
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
# 全自动
|
|
|
|
|
|
既然一次抓取成功了,那能不能全自动呢?
|
|
|
|
|
|
当然可以了。还记得返回中的`right`的内容吗?这是下一节的ID和标题。所以我们只需要在文档保存后,拿到这个ID,然后跳转到下一节即可。
|
|
|
|
|
|
|
|
|
|
|
|
在下载完成的地方增加以下代码
|
|
|
|
|
|
```js
|
|
|
|
|
|
if (data.data.neighbors.right.id) {
|
|
|
|
|
|
var nextId = data.data.neighbors.right.id;
|
|
|
|
|
|
window.location.href = "https://time.geekbang.org/column/article/" + nextId;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
然后再增加一个执行的代码
|
|
|
|
|
|
```
|
|
|
|
|
|
setInterval(function () { btn.click(); }, 10000);
|
|
|
|
|
|
```
|
|
|
|
|
|
为什么10秒呢,因为请求过于频繁会强制退出登录。所以控制一下速度。
|
|
|
|
|
|
|
|
|
|
|
|
# 完整脚本
|
|
|
|
|
|
|
|
|
|
|
|
```json
|
|
|
|
|
|
// ==UserScript==
|
|
|
|
|
|
// @name copy to markdown
|
|
|
|
|
|
// @namespace http://tampermonkey.net/
|
|
|
|
|
|
// @version 0.1
|
|
|
|
|
|
// @match https://time.geekbang.org/column/article/*
|
|
|
|
|
|
// @description try to take over the world!
|
|
|
|
|
|
// @author You
|
|
|
|
|
|
// @require https://unpkg.com/turndown/dist/turndown.js
|
|
|
|
|
|
// @require https://cdn.bootcss.com/jquery/1.12.4/jquery.min.js
|
|
|
|
|
|
// @grant none
|
|
|
|
|
|
// ==/UserScript==
|
|
|
|
|
|
|
|
|
|
|
|
(function () {
|
|
|
|
|
|
'use strict';
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
let btn = document.createElement("button");
|
|
|
|
|
|
btn.innerHTML = "下载";//innerText也可以,区别是innerText不会解析html
|
|
|
|
|
|
btn.style = "position: fixed;z-index: 999; left: 90%; top: 20px;";
|
|
|
|
|
|
|
|
|
|
|
|
btn.onclick = function () {
|
|
|
|
|
|
//code
|
|
|
|
|
|
saveContext()
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
document.body.append(btn);
|
|
|
|
|
|
setInterval(function () { btn.click(); }, 10000);
|
|
|
|
|
|
function saveContext() {
|
|
|
|
|
|
var url = window.location.href
|
|
|
|
|
|
var id = url.replace("https://time.geekbang.org/column/article/", "")
|
|
|
|
|
|
var json = { "id": id, "include_neighbors": true, "is_freelyread": true }
|
|
|
|
|
|
|
|
|
|
|
|
$.ajax({
|
|
|
|
|
|
url: "https://time.geekbang.org/serv/v1/article",
|
|
|
|
|
|
data: JSON.stringify(json),
|
|
|
|
|
|
type: "POST",
|
|
|
|
|
|
dataType: "json",
|
|
|
|
|
|
contentType: "application/json",
|
|
|
|
|
|
success: function (data) {
|
|
|
|
|
|
console.log(data);
|
|
|
|
|
|
var context = data.data.article_content;
|
|
|
|
|
|
var title = data.data.article_title;
|
|
|
|
|
|
|
|
|
|
|
|
const link = document.createElement('a');
|
|
|
|
|
|
|
|
|
|
|
|
var textBlob = new Blob([context], { type: 'text/plain' });
|
|
|
|
|
|
|
|
|
|
|
|
link.setAttribute('href', URL.createObjectURL(textBlob));
|
|
|
|
|
|
link.setAttribute('download', title + ".html");
|
|
|
|
|
|
link.click();
|
|
|
|
|
|
|
|
|
|
|
|
if (data.data.neighbors.right.id) {
|
|
|
|
|
|
var nextId = data.data.neighbors.right.id;
|
|
|
|
|
|
window.location.href = "https://time.geekbang.org/column/article/" + nextId;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
}
|
|
|
|
|
|
});
|
|
|
|
|
|
}
|
|
|
|
|
|
})();
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
# 转换成markdown
|
|
|
|
|
|
|
|
|
|
|
|
没有在脚本中保存为markdown,因为需要处理图片之类的信息。决定事后用Java代码处理。
|
|
|
|
|
|
|
|
|
|
|
|
设想处理流程如下:
|
|
|
|
|
|
1. 解析Html讲图片从网络地址,换成本地地址
|
|
|
|
|
|
2. 转换成Markdown
|
|
|
|
|
|
|
|
|
|
|
|
## 调研
|
|
|
|
|
|
java中的html解析,直接用Jsoup
|
|
|
|
|
|
markdown转换使用CopyDown
|
|
|
|
|
|
|
|
|
|
|
|
这两个包的Maven坐标:
|
|
|
|
|
|
```xml
|
|
|
|
|
|
<dependency>
|
|
|
|
|
|
<groupId>io.github.furstenheim</groupId>
|
|
|
|
|
|
<artifactId>copy_down</artifactId>
|
|
|
|
|
|
<version>1.0</version>
|
|
|
|
|
|
</dependency>
|
|
|
|
|
|
<dependency>
|
|
|
|
|
|
<groupId>org.jsoup</groupId>
|
|
|
|
|
|
<artifactId>jsoup</artifactId>
|
|
|
|
|
|
<version>1.13.1</version>
|
|
|
|
|
|
</dependency>
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
## 开始编写
|
|
|
|
|
|
|
|
|
|
|
|
### 文件的读取及写入
|
|
|
|
|
|
|
|
|
|
|
|
主要是提供一个文件的读取和写入方法
|
|
|
|
|
|
|
|
|
|
|
|
```java
|
|
|
|
|
|
|
|
|
|
|
|
public static String getFileString(File file) {
|
|
|
|
|
|
try {
|
|
|
|
|
|
if (file.exists() && file.isFile()) {
|
|
|
|
|
|
List<String> lines = Files.readAllLines(Paths.get(file.toURI()), StandardCharsets.UTF_8);
|
|
|
|
|
|
StringBuilder sb = new StringBuilder();
|
|
|
|
|
|
for (String line : lines) {
|
|
|
|
|
|
sb.append(line).append("\n");
|
|
|
|
|
|
}
|
|
|
|
|
|
return sb.toString();
|
|
|
|
|
|
} else {
|
|
|
|
|
|
return "未找到文件";
|
|
|
|
|
|
}
|
|
|
|
|
|
} catch (Exception e) {
|
|
|
|
|
|
logger.error("getFileString error!", e);
|
|
|
|
|
|
return "读取出现异常";
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
public static void saveToFile(File file, String context) {
|
|
|
|
|
|
try {
|
|
|
|
|
|
FileOutputStream fileOutputStream = null;
|
|
|
|
|
|
if (!file.exists()) {
|
|
|
|
|
|
file.createNewFile();
|
|
|
|
|
|
}
|
|
|
|
|
|
fileOutputStream = new FileOutputStream(file);
|
|
|
|
|
|
fileOutputStream.write(context.getBytes(StandardCharsets.UTF_8));
|
|
|
|
|
|
fileOutputStream.flush();
|
|
|
|
|
|
fileOutputStream.close();
|
|
|
|
|
|
} catch (Exception e) {
|
|
|
|
|
|
e.printStackTrace();
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
### 保存图片文件
|
|
|
|
|
|
|
|
|
|
|
|
```java
|
|
|
|
|
|
private static String downFile(File assetsDir, String remoteUrl) {
|
|
|
|
|
|
try {
|
|
|
|
|
|
String uuid = UUID.randomUUID().toString().replace("-", "")+".jpg";
|
|
|
|
|
|
runtime.exec("curl -o " + uuid + " \"" + remoteUrl + "\"", null, assetsDir);
|
|
|
|
|
|
return uuid;
|
|
|
|
|
|
} catch (IOException e) {
|
|
|
|
|
|
throw new RuntimeException(e);
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
此处极为省事,直接执行curl保存到目录中
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
### markdown转换代码
|
|
|
|
|
|
```java
|
|
|
|
|
|
|
|
|
|
|
|
public static String htmlTansToMarkdown(String htmlStr) {
|
|
|
|
|
|
OptionsBuilder optionsBuilder = OptionsBuilder.anOptions();
|
|
|
|
|
|
Options options = optionsBuilder.withBr("-").withCodeBlockStyle(CodeBlockStyle.FENCED)
|
|
|
|
|
|
// more options
|
|
|
|
|
|
.build();
|
|
|
|
|
|
CopyDown converter = new CopyDown(options);
|
|
|
|
|
|
return converter.convert(htmlStr);
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
可以参见官方文档:[copy-down](https://github.com/furstenheim/copy-down)
|
|
|
|
|
|
|
|
|
|
|
|
### 解析并替换图片地址
|
|
|
|
|
|
|
|
|
|
|
|
传入保存的文件夹,原始的HTML文件
|
|
|
|
|
|
|
|
|
|
|
|
```java
|
|
|
|
|
|
|
|
|
|
|
|
public static void convert(String dir, File file) {
|
|
|
|
|
|
File assetsDir = new File(dir + "/assets");
|
|
|
|
|
|
assetsDir.mkdirs();
|
|
|
|
|
|
String html = FileUtils.getFileString(file);
|
|
|
|
|
|
|
|
|
|
|
|
Document doc = Jsoup.parse(html);
|
|
|
|
|
|
Elements imageList = doc.getElementsByTag("img");
|
|
|
|
|
|
Elements h1List = doc.getElementsByTag("title");
|
|
|
|
|
|
for (Element element : imageList) {
|
|
|
|
|
|
String url = element.attributes().get("src");
|
|
|
|
|
|
String uuid = downFile(assetsDir, url);
|
|
|
|
|
|
element.attributes().remove("src");
|
|
|
|
|
|
element.attributes().add("src", "assets/" + uuid);
|
|
|
|
|
|
element.attributes().remove("title");
|
|
|
|
|
|
}
|
|
|
|
|
|
String markdown = htmlTansToMarkdown(doc.outerHtml());
|
|
|
|
|
|
|
|
|
|
|
|
FileUtils.saveToFile(new File(dir + "/" + file.getName().replace(".html", ".md")), markdown);
|
|
|
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
至此文件已经生成了。但是我们有一个目录的文件需要执行啊,所以在main方法遍历文件夹
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
### 遍历文件夹
|
|
|
|
|
|
|
|
|
|
|
|
```java
|
|
|
|
|
|
public static void main(String[] args) {
|
|
|
|
|
|
File file = new File("HTML路径");
|
|
|
|
|
|
String dir = "markdown保存目录";
|
|
|
|
|
|
if (file.isDirectory()) {{
|
|
|
|
|
|
for (File listFile : file.listFiles()) {
|
|
|
|
|
|
convert(dir, listFile);
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
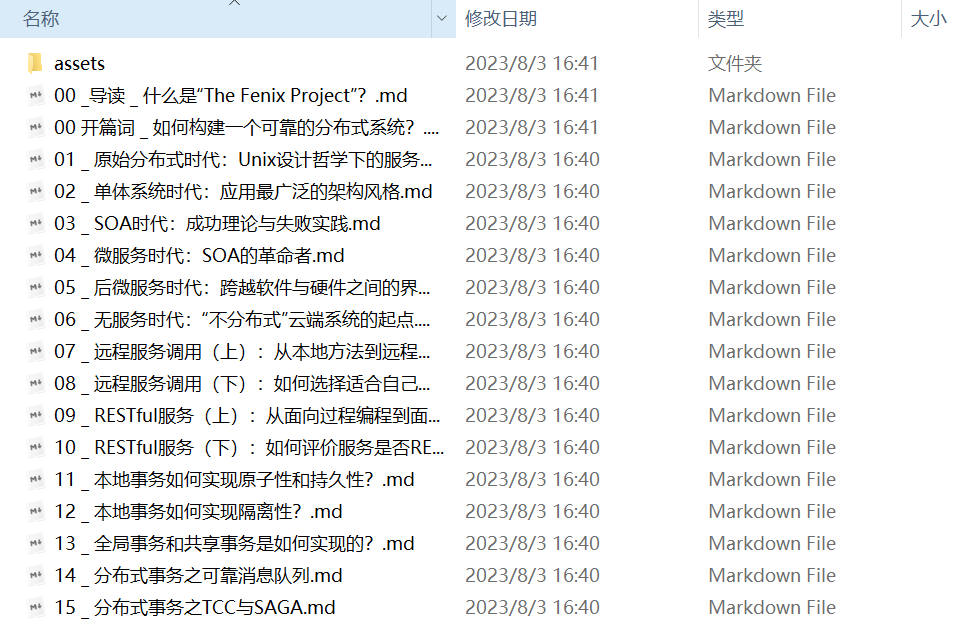
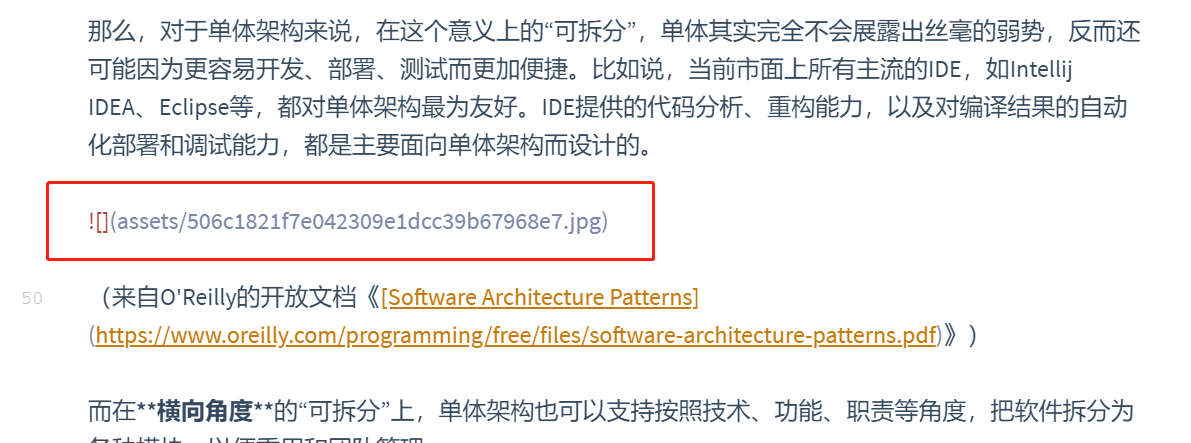
查看执行效果:
|
|
|
|
|
|
|
|
|
|
|
|
目录:
|
2023-12-05 13:42:32 +08:00
|
|
|
|
|
2023-08-03 18:38:21 +08:00
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
图片:
|
2023-12-05 13:42:32 +08:00
|
|
|
|
|
2023-08-03 18:38:21 +08:00
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|